How to Parse Text – TechCult

If you have learned a few computer programming languages, you might have heard the term, parsing text. This is used to simplify the complex data values of the file. The article helps you in knowing how to parse text using the language. In addition to this, if you have faced error in parse text x, you will know how to fix parse error in the article.

How to Parse Text
In this article we have shown a full guide to parse text through various ways and also briefly gave introduction to parsing text.
What is Parsing Text?
Before delving to learn the concepts of parsing text using any code. It is important to know about the basics of the language and the coding.
NLP or Natural Language Processing
To parse text, Natural Language Processing or NLP, which is a sub-field of the Artificial Intelligence domain is utilized. Python language, which is one of the languages that belong to the category is used to parse text.
The NLP codes enable computers to understand and process human languages to make them suitable for various applications. To apply ML or Machine Learning techniques to the language, the unstructured text data has to be converted into structured tabular data. For completing the parsing activity, the Python language is used to alter the program codes.
What is Parsing Text?
Parsing text simply means converting the data from one format to another format. The format in which the file is saved shall be parsed or converted to a file in a different format to enable the user to use it in various applications.
- In other words, the process means analyzing the string or a text and convert into logical components by altering the format of the file.
- Some rules of the Python language are utilized to complete this common programming task. While parsing text, the given series of text is broken down into smaller components.
What are the Reasons to Parse Text?
The reasons for which the text has to be parsed are given in this section and it is a pre-requisite knowledge before knowing how to parse text.
- All computerized data will not be in the same format and may differ according to various applications.
- The data formats vary for various applications and an incompatible code would lead to this error.
- There is no individual universal computer program for selecting the data of all the data formats.
Method 1: Through DataFrame Class
The DataFrame Class of the Python language has all the required functions to parse text. This in-built library houses the necessary codes to parse data of any format to another format.
Brief Introduction of DataFrame Class
DataFrame Class is a feature-rich data structure, which is used as a data analysis tool. This is a powerful data analysis tool that can be used to analyze data with minimal effort.
- The code is read into the pandas DataFrame to perform the analysis in the Python language.
- The Class comes with numerous packages provided by the pandas which are used by Python data analysts.
- The feature of this class is an abstraction, a code in which the internal functionality of the function is hidden from the users, of the NumPy library. The NumPy library is a python library that encompasses the commands and functions for working with arrays.
- The DataFrame class can be used to render a two-dimensional array with multiple row and column indices. These indices help in storing multi-dimensional data, and hence, are called, MultiIndex. These have to be altered to know how to fix parse error.
The pandas of the Python language help in performing the SQL or database-style operations with utmost perfection to avoid error in parse text x. It also contains some IO tools that help in analyzing the files of CSV, MS Excel, JSON, HDF5, and other data formats.
Also Read: Fix Error Occurred While Trying to Proxy Request
Process of Parsing Text using DataFrame Class
To know how to parse text, you can use the standard process using the DataFrame Class given in this section.
- Decipher the data format of the input data.
- Decide the output data of the data such as CSV or Comma Separated Value.
- Write on the code a primitive data type like list or dict.
Note: Writing the code on an empty DataFrame can be tedious and complex. The pandas allow in creating the data on the DataFrame class from these data types. Hence, the data in the primitive data type can be easily parsed to the required data format.
- Analyse the data using the data analysis tool, pandas DataFrame, and print the result.
Option I: Standard Format
The standard method to format any file with a certain data format such as CSV is explained here.
- Save the file with the data values locally on your PC. For instance, you can name the file data.txt.
- Import the file in pandas with a specific name and import the data to another variable. For instance, the pandas of the language are imported into the name pd in the code given.
- The import should have a complete code with the detail of the name of the input file, the function, and the input file format.
Note: Here, the variable named res is used to perform the read function of the data in the file data.txt using the pandas imported in pd. The data format of the input text is specified in the CSV format.
- Call the named file type and analyze the parsed text on the printed result. For instance, the command res after the command line execution will help in printing the parsed text.
An example code for the process explained above is given below and will help in understanding how to parse text.
import pandas as pd res = pd.read_csv(‘data.txt’) res
In this case, if you input the data values in the file data.txt such as [1,2,3], it would be parsed and displayed as 1 2 3.
Option II: String Method
If the text given to the code contains only strings or alpha characters, the special characters in the string such as commas, space, etc., can be used to separate and parse the text. The process is similar to the common internal string operations. To find how to fix parse error, you have to follow the process of parsing the text using this option is explained below.
- The data is extracted from the string and all the special characters that separate the text are noted.
For instance, in the code given below, the special characters in the string my_string, which are, ‘,’ and ‘:’ are identified. This process has to be done carefully to avoid error in parse text x.
- The text in the string is split individually based on the values and the position of the special characters.
For instance, the string is split into text data values based on the special characters identified using the split command.
- The data values of the string are printed alone as the parsed text. Here, the print statement is used to print the parsed data value of the text.
The sample code for the process explained above is given below.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
In this case, the result of the parsed string would be displayed as shown below.
Names: [‘Tech’, ‘computer’]
To get better clarity and know how to parse text while using the string text, a for loop is utilized and the code is modified as follows.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
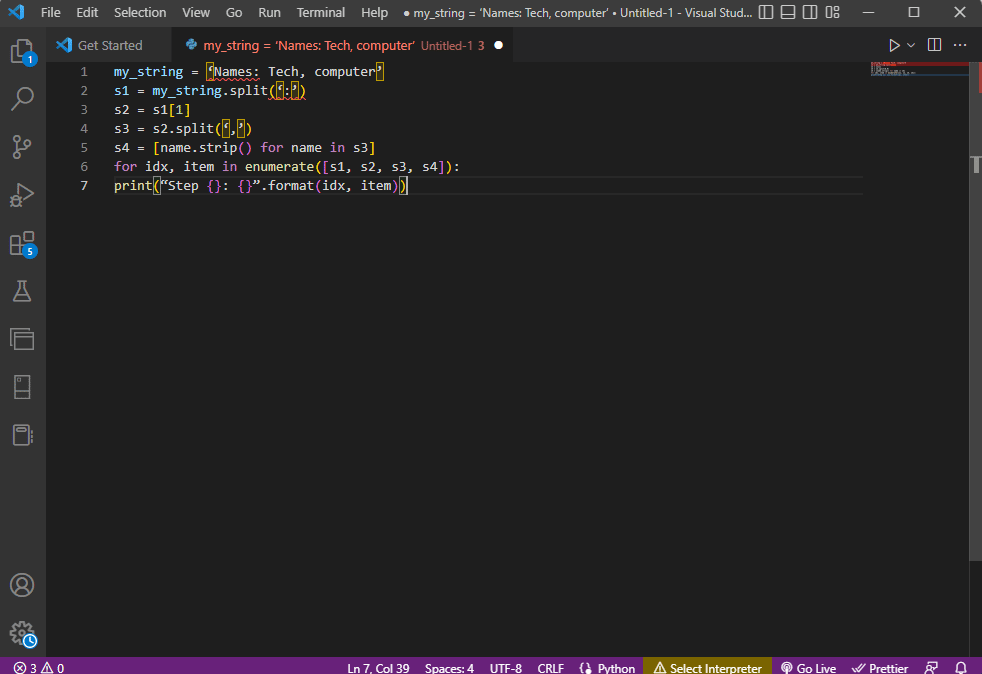
The result of the parsed text for each of these steps is displayed as given below. You can note that, in Step 0, the string is separated based on the special character : and the text data values are separated based on the character in further steps.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Option III: Parsing Complex File
In most instances, the file data that needs to be parsed contains varying data types and data values. In this case, it might be difficult to parse the file using the methods explained earlier.
The features of parsing the complex data in the file are to make the data values get displayed in a tabular format.
- The Title or Metadata of the values is printed at the top of the file,
- The variables and fields are printed in the output in a tabular form, and
- The data values form a compound key.
Before delving into learning how to parse text in this method, it is necessary to learn a few basic concepts. The parsing of the data values is done based on regular expressions or Regex.
Regex Patterns
To know how to fix parse error, you have to ensure that the regex patterns in the expressions are proper. The code to parse the data values of the strings would involve the common Regex patterns listed below in this section.
- ‘d’ : matches the decimal digit in the string,
- ‘s’ : matches the whitespace character,
- ‘w’: matches the alphanumeric character,
- ‘+’ or ‘*’ : performs a greedy match by matching one or more characters in the strings,
- ‘a-z’ : matches the lowercase groups in the text data values,
- ‘A-Z’ or ‘a-z’ : matches the upper and lowercase groups of the string, and
- ‘0-9’ : matches the numerical values.
Regular Expressions
Regular expression modules are a major part of the pandas package in the Python language and a wrong re can lead to an error in parse text x. It is a tiny language embedded inside Python to find the string pattern in the expression. Regular Expressions or Regex are strings with special syntax. It allows the user to match patterns in other strings based on the values in the strings.
The Regex is created based on the data type and the requirement of the expression in the string, such as ‘String = (.*)n. The regex is used before the pattern in every expression. The symbols used in the regular expressions are listed below and will help in knowing how to parse text.
- . : to retrieve any character from the data,
- * : use zero or more data from the previous expression,
- (.*) : to group a part of the regular expression within the parentheses,
- n : Create a new line character at end of the line in code,
- d : create a short integral value in the range 0 to 9,
- + : use one or more data from the previous expression, and
- | : create a logical statement; used for or expressions.
RegexObjects
The RegexObject is a return value for the compile function and is used to return a MatchObject if the expression matches the match value.
1. MatchObject
As the Boolean value of the MatchObject is always True, you can use an if statement to identify the positive matches in the object. In the case of using the if statement, the group referred to by the index is used to find out the match of the object in the expression.
- group() returns one or more subgroups of match,
- group(0) returns the entire match,
- group(1) returns the first parenthesized subgroup, and
- While referring to multiple groups, we should use a python specific extension. This extension is used to specify the name of the group in which the match has to be found. The specific extension is provided within the parenthesized group. For instance, the expression, (?P<group1>regex1) would refer to the specific group with the name group1 and check for the match in the regular expression, regex1. To learn how to fix parse error, you have to check if the group is pointed correctly.
2. Methods of MatchObject
While finding how to parse text, it is important to know that the MatchObject has two basic methods as listed below. If the MatchObject is found in the expression specified, it would return its instance, else, it would return None.
- The match(string) method is used to find the matches of the string at the beginning of the regular expression, and
- The search(string) method is used to scan through the string to find the location for a match in the regular expression.
Regular Expression Functions
Regex Functions are code lines that are used to perform a certain function as specified by the user from the set of data values procured.
Note: To write the functions, raw strings are used for the regular expressions to avoid error in parse text x. This is done by adding the subscript r before each pattern in the expression.
The common functions used in the expressions are explained below.
1. re.findall()
This function returns all the patterns in the string if a match is found and returns an empty list if no match is found. For instance, the function, string = re.findall(‘[aeiou]’, regex_filename) is used to find the vowel occurrence in the filename.
2. re.split()
This function is used to split the string in case of a match with a character specified such as space is found. In case of no match is found, it returns an empty string.
3. re.sub()
The function substitutes the matched text with the contents of the replace variable given. Contrary to other functions, if no pattern is found, the original string is returned.
4. re.search()
One of the basic functions to help in learning how to parse text is the search function. It helps in searching the pattern in the string and returning the match object. If the search fails in identifying the match, no value is returned.
5. re.compile(pattern)
This function is used to compile regular expression patterns into a RegexObject, which was discussed earlier.
Other Requirements
The listed requirements are an additional feature used by advanced programmers in data analysis.
- To visualize the regular expression, regexper is used, and
- To test the regular expression, regex101 is used.
Also Read: How to Install NumPy on Windows 10
Process of Parsing Text
The method to parse the text in this complex option is described as given below.
- The foremost step is to understand the input format by reading the content of the file. For instance, the with open and read() functions are used to open and read the content of the file named sample. The sample file has the contents from the file file.txt; to learn how to fix parse error, the file must be read completely.
- The contents of the file are printed to analyze the data manually to find out the metadata of the values. Here, the print() function is used to print the contents of the sample file.
- The required data packages to parse the text are imported to the code and a name is given to the class for further coding. Here, the regular expressions and pandas are imported.
- The regular expressions required for the code are defined in the file by including the regex pattern and regex function. This allows the text object or corpus to take the code for data analysis.
- To know how to parse text, you can refer to the example code given here. The compile() function is used to compile the string from the group stringname1 of the file filename. The function to check for matches in the regex is used by the command ief_parse_line(line),
- Line parser for the code is written using the def_parse_file(filepath), in which the defined function checks for all the regex matches in the function specified. Here, the regex search() method searches for the key rx in the file filename and returns the key and match of the first matching regex. Any issue with the step can lead to an error in parse text x.
- The next step is to write a File Parser using the file parser function, which is def_parse_file(filepath). An empty list is created to collect the data of the code, as data = [], the match is checked at each line by match = _parse_line(line), and the exact value data is returned based on the data type.
- To extract the number and value for the table, the command line.strip().split(‘,’) is used. The row{} command is used to create a dictionary with the row of data. The data.append(row) command is used to comprehend the data and parse it to a tabular format.
The command data = pd.DataFrame(data) is used to create a pandas DataFrame from the dict values. Alternatively, you can use the following commands for the respective purpose as stated below.
- data.set_index([‘string’, ‘integer’], inplace=True) to set the index of the Table.
- data = data.groupby(level=data.index.names).first() to consolidate and remove nans.
- data = data.apply(pd.to_numeric, errors=’ignore’) to upgrade score from float to integer value.
The final step to know how to parse text is to test the parser using the if statement by assigning the values to a variable data and printing it using the print(data) command.
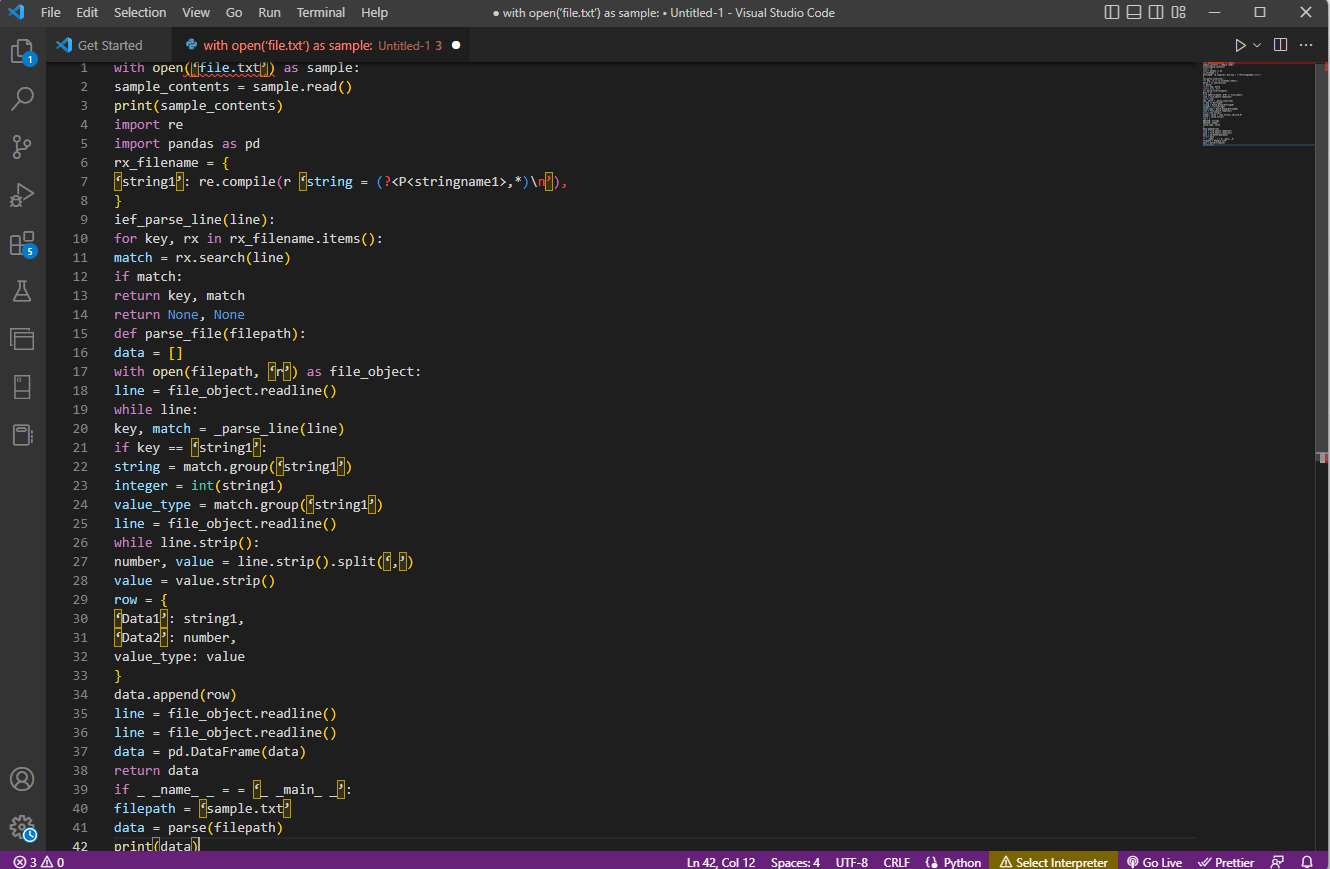
The example code for the explanation above is given here.
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Method 2: Through Word Tokenization
The process of converting a text or corpus into tokens or smaller pieces based on certain rules is called Tokenization. To learn how to fix parse error, it is important to analyze the word tokenization commands in the code. Similar to the regex, own rules can be created in this method and it helps in text pre-processing tasks such as mapping parts of speech. Also, activities like finding and matching common words, cleaning text, and getting the data ready for advanced text analytics techniques like sentiment analysis are performed in this method. If the tokenization is improper, error in parse text x may occur.
Ntlk Library
The process takes the help of the popular language toolkit library called nltk, which has a rich set of functions for performing many NLP jobs. These can be downloaded through the Pip or Pip Installs Packages. To know how to parse text, you can use the base pack of the Anaconda distribution which includes the library by default.
Forms of Tokenization
The common forms of this method are word tokenization and sentence tokenization. Owing to the word-level token, the former prints one word only once, while the latter prints the word at the sentence level.
Process of Parsing Text
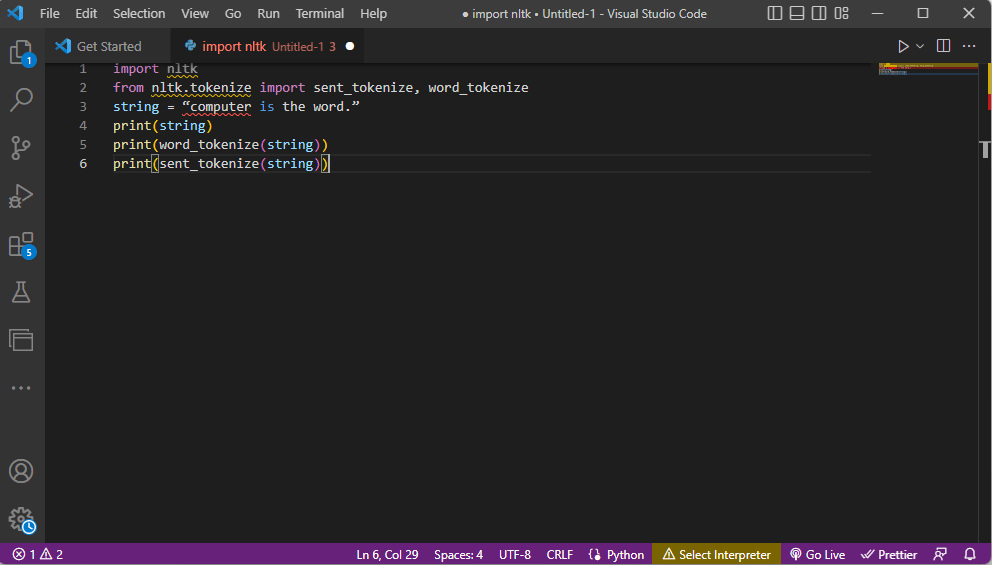
- The ntlk toolkit library is imported and the tokenization forms are imported from the library.
- A string is given and the commands to perform the tokenization are given.
- While the string is printed, the output would be computer is the word.
- In the case of word tokenization or word_tokenize(), each of the word in the sentence is printed individually within the ‘’ and is separated by a comma. The output for the command would be the ‘computer’, ‘is’, ‘the’, ‘word’, ‘.’
- In the case of sentence tokenization or sent_tokenize(), the individual sentences are placed within the ‘’ and the word repetition is allowed. The output for the command would be ‘computer is the word.’
The code explaining the steps for tokenization above is given here.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Also Read: How to Fix javascript:void(0) Error
Method 3: Through DocParser Class
Similar to the DataFrame Class, the Class DocParser can be used to parse the text in the code. The class allows you to call the parse function with the filepath.
Process of Parsing Text
To know how to parse text using the DocParser Class, follow the instructions given below.
- The get_format(filename) function is used to extract the file extension, return it to a set variable for the function, and pass it to the next function. For instance, p1 = get_format(filename) would extract the file extension of filename, set it to the variable p1, and pass it to the next function.
- A logical structure with other functions is constructed using the if-elif-else statements and functions.
- If the file extension is valid and the structure is logical, the get_parser function is used to parse the data in the file path and return the string object to the user.
Note: To know how to fix parse error, this function must be implemented correctly.
- The parsing of the data values is done with the file extension of the file. The concrete implementation of the class, which are parse_txt or parse_docx is used to generate string objects from the parts of the given file type.
- The parsing can be done for files of other readable extensions such as parse_pdf, parse_html, and parse_pptx.
- The data values and interface can be imported into applications with import statements and instantiate a DocParser object. This can be done by parsing files in the Python language, such as parse_file.py. This operation has to be done carefully to avoid error in parse text x.
Method 4: Through Parse Text Tool
The Parse text tool is used to extract specific data from variables and map them to other variables. This is independent of any other tools used in a task and the BPA Platform tool is used to consume and output variables. Use the link given here to access the Parse Text Tool online and use the answers given earlier on how to parse text.
Method 5: Through TextFieldParser (Visual Basic)
The TextFieldParser utilized objects to parse and process very large files that are structured and delimited. The width and column of text such as log files or legacy database information can be used in this method. The parsing method is similar to iterating the code over a text file and is mainly used to extract fields of text similar to string manipulation methods. This is done to tokenize delimited strings and fields of various widths using the defined delimiter such as comma or tab space.
Functions to Parse Text
The following functions can be used to parse the text in this method.
- To define a delimiter, the SetDelimiters is used. For instance, the command testReader.SetDelimiters (vbTab) is used to set tab space as the delimiter.
- To set a field width to a positive integer value to a fixed field width of text files, you can use the testReader.SetFieldWidths (integer) command.
- To test the field type of the text, you can use the following command testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Methods to Find MatchObject
There are two basic methods to find the MatchObject in the code or the parsed text.
- The first method is to define the format and loop through the file using the ReadFields method. This method would help in processing each line of the code.
- The PeekChars method is used to check each field individually before reading it, define multiple formats, and react.
In either case, if a field does not match the specified format while performing the parsing or finding how to parse text, a MalformedLineException exception is returned.
Pro Tip: How to Parse Text Through MS Excel
As a final and simple method to parse the text, you can use the MS Excel app as a parser to create tab-delimited and comma-delimited files. This would help in cross-checking with your parsed result and help in finding how to fix parse error.
1. Select the data values in the source file and press the Ctrl + C keys together to copy the file.
2. Open the Excel app using the windows search bar.
3. Click on the A1 cell and press the Ctrl + V keys simultaneously to paste the copied text.
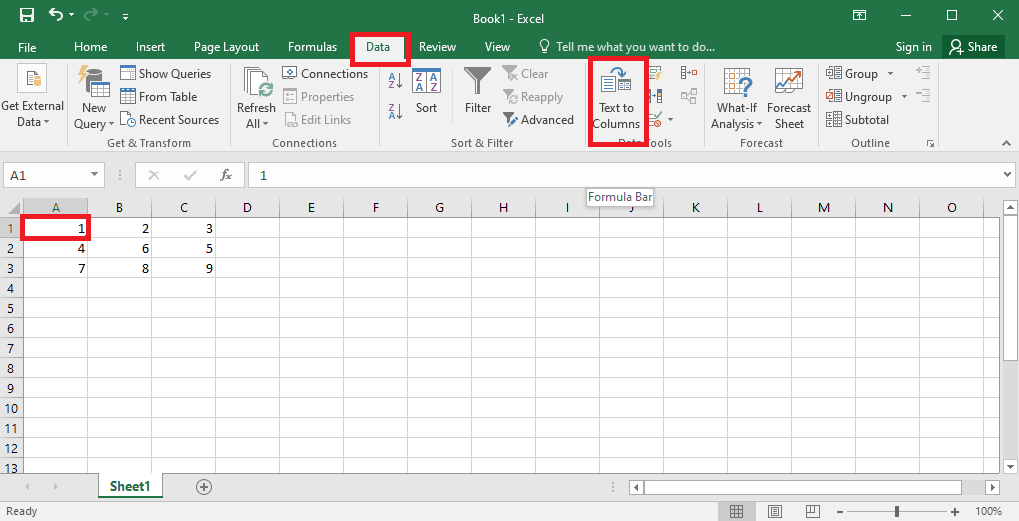
4. Select the A1 cell, navigate to the Data tab, and click on the Text to columns option in the Data Tools section.
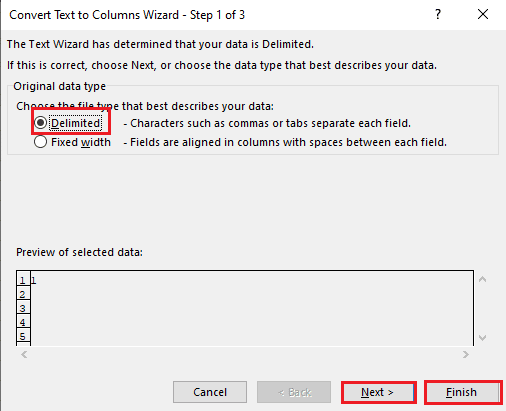
5A. Select the Delimited option if a comma or tab space is used as the separator, and click on the Next and Finish buttons.
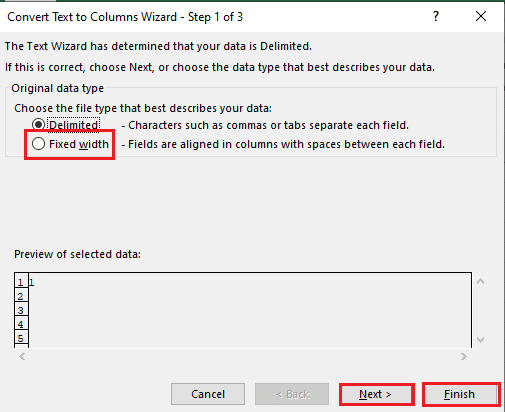
5B. Select the Fixed width option, assign a value for the separator, and click on the Next and Finish buttons.
Also Read: How to Fix Move Excel Column Error
How to Fix Parse Error
Error in parse text x may occur on Android devices as, Parse Error: There was a problem parsing the package. This usually occurs when the app fails to install from the Google Play Store or while running a third-party app.
The error text x may occur if the list of character vectors is looped and other functions form a linear model for calculating the data values. The error message is Error in parse(text = x, keep.source = FALSE):<text>:2.0:unexpected end of input 1:OffenceAgainst ~ ^.
You can read the article on how to fix parse error on Android to learn the causes and methods to fix the error.
Apart from the solutions in the guide, you can try the following fixes.
- Re-downloading the .apk file or restoring the name of the file.
- Restoring changes in the Androidmanifest.xml file, if you have expert-level programming skills.
Recommended:
The article helps in teaching how to parse text and to learn how to fix parse error. Let us know which method helped fix error in parse text x and which method of parsing is preferred. Please share your suggestions and queries in the comments section below.